실습내용 정리
✅ 0501실습
머신러닝의 지도학습의 분류를 사용하는 Scikit-learn API 기초와 DecisionTree 실습 => (수치데이터만 사용)
✅ 0502 실습
💡범주형 데이터 => 수치 데이터 (인코딩)
💡One-Hot-Encoding(pd.get_dummies)
💡RandomForest
🤔loss ❓
예측값과 실제값(레이블)의 차이
💡손실함수(Loss function)는 예측값과 실제값(레이블)의 차이(loss)를 구하는 기준.
=> 머신러닝 모델 학습에서 필수 구성요소
=> 손실함수로 인해 모델의 성능이 달라짐
이러한 이유로 머신러닝 모델을 구현하는 사람들은 어떠한 손실함수가 최적일지 고민
🤔df["Churn"].value_counts(1)
df["Churn"].value_counts(normalize=True)
=> 같은결과반환!
🤔모델의 정확도가 99%가 나왔다…?
👉🏻 정답을 학습데이터에 포함시켰을 수도 있다!
🤔 train, test의 피처를 동일하게 만들어주어야 학습과 예측을 할 때 오류가 생기지 않음!
train, test를 따로 인코딩하면 컬럼 순서나 개수가 달라질 수 있다.
다른 피처를 사용하면 학습했을 때 오류가 발생!! -> train으로 맞춰주는 작업 필요
scikit-learn에서 fit, transform을 할 때 trian에만 fit을 해주는 이유와도 같음
✅ 0503 실습
One-Hot-Encoding(scikit-learn), 언더피팅, 오버피팅을 평가할 때 train, test 두 가지 데이터에 대한 점수 비교
=> 기존에는 test 데이터에 대해서만 평가. train 데이터로도 평가해볼 예정입니다.
cross validation 기법을 사용해서 평가
+ *구독형 서비스에서 머신러닝을 통해 이탈률 예측 분석
*구독형 서비스 => 통신사, 휴대폰, 정수기, 월별로 렌탈을 해서 사용하는 물건, 사무기기 등
One Hot Encoding
✅ One Hot Encoding 이란 ❓
📝 사람이 이해할 수 있는 데이터 => 컴퓨터도 이해( 숫자 데이터로 변환 )
📝 데이터를 수많은 0(False)과 하나의 1(True)로 데이터를 구별
📝 1) 머신러닝에서 분류 모델을 다룸
2) 데이터 분석에서 범주형 데이터 혹은 카테고리컬한 문제
📊 우리는 데이터를 컴퓨터가 인식할 수 있도록 변환
=>데이터 형태는 0과 1로 이루어졌기 때문에 컴퓨터가 인식하고 학습하기에 용이하다.
📝 매우 기초적이면서도 아주 흔하게 사용되는 *Feature Enginieering 기법
📝 딥러닝, 자연어처리, 데이터 마이닝 등 많은 분야에서 사용되고 있다.
📌 feature engineering이란? 데이터 전처리 기법 중 하나
변수를 변환하거나 새로운 변수를 생성하는 등의 과정을 통해 유의미한 변수로 만들어내는 것
📝 One-Out-of-N Encoding or 가변수
=> 범주형 변수를 이진 벡터로 표시

✅ One Hot Encoding 결측치
📝 One Hot Encoding을 할 때 결측치는 고려X
=> 결측치를 원핫인코딩에 반영하고자 한다면 문자 데이터 "NA" or "없음" 등의 값 생성
📝 결측치를 채우는 방법도 있지만 결측치가 너무 많은데 해당 변수를 사용하고자 할 때는❓
=> 범주화 해서 사용하는 방법
📝 요금을 높음, 중간, 낮음 등으로 qcut, cut 으로 범주화
=> One Hot Encoding 하면 결측치를 채우지 않고 기존 값만 활용
=> 예를 들어 사용기간(Tenure) 는 약정 기간별로 해지가 주로 되는 기간을 나눠서 구간화 하는 것도 방법
✅ One Hot Encoding 장점과 단점
| 장점 | 단점 |
| 모든 머신러닝 알고리즘에서 사용 가능 | 카테고리 수가 많은 경우, 변수의 차원증가 -> 차원의 저주 문제 / 모델 학습 속도 저하 |
| 범주형 변수 => 수치형 변수 모델이 변수 간 상관관계를 파악 |
카테고리 수가 적은 경우 *희소 행렬 생성 -> 데이터셋 크기가 커져 메모리, 처리 속도에 부담 |
| 범주형 변수의 카테고리 수가 많아져도 적용 |
📌 희소행렬
희소 행렬(Sparse Matrix)은 행렬의 원소 중에 많은 항들이 '0'으로 구성되어 있는 행렬
희소 행렬의 대부분의 항은 '0'으로 이루어져 있어, 실제 사용하지 않는 메모리 공간으로 인해 메모리 낭비가 발생

✅ One Hot Encoding 종류
Sklearn에서 제공하는 Encoding 종류
1) LabelEncoder()
2) OneHotEncoder([, categories, ...])
3) OrdinalEncoder([, ...])
📌Ordinal encoding 링크 : https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.OrdinalEncoder.html
✅ One Hot Encoding의 한계
단어의 개수가 늘어날 수록, 벡터를 저장하기 위해 필요한 공간이 계속 늘어남
=> 다른 표현으로는 벡터의 차원이 늘어난다고 표현
✅ get_dummies()
=> 범주형 변수를 더미/지시 변수로 변환
https://pandas.pydata.org/docs/reference/api/pandas.get_dummies.html
Series.str.get_dummies
시리즈를 더미 코드로 변환
from_dummies()
더미 코드를 범주형으로 변환
데이터 누수(Data Leakage)
✅ Data Leakage
📝 미래에 대한 전혀 알 수 없는 대한 정보가 모델 학습에서 사용된 경우
📝 Test 데이터가 모델의 학습에 이용된 경우
📝 학습 데이터에 대상에 대한 정보가 포함, but 예측에 모델을 사용할 때 유사한 데이터를 사용할 수 없을 때 발생
=> 학습 세트(및 검증 데이터)의 성능은 ▲ , 실제 운영 환경에서는 모델의 성능 ▼
❗ 누수가 발생하면 모델을 사용하여 의사 결정을 내리기 전까지는 모델이 정확해보임
=> 그 이후에는 모델이 매우 부정확
👨💼 해커톤에서의 데이터 누수 ▼
해커톤(경진대회) 특성 상, 리더보드 제출을 위해 추론에 사용될 test 데이터들이 사전에 주어지지만, 실제 모델을 서비스하는 환경에서는 test 데이터들이 어떠한 데이터들이 몇개가 입력으로 들어올 지 전혀 알 수 없습니다.
"""
이번 '스마트 공장 제품 품질 상태 분류 AI 온라인 해커톤'의 데이터의 경우, Train 데이터의 경우 약 22년 6월 13일 ~ 22년 9월 8일까지의 데이터로 구성되어 있고, Test 데이터는 약 22년 9월 9일 ~ 22년 11월 5일까지의 데이터로 구성되어 있습니다.
"""
👨💼 다음 중 경진대회 등에서 Data Leakage 로 보는 항목이 아닌 것은 무엇일까요 ❓
1) Label Encoding 시 Test 데이터로부터 Encoder를 fit 시키는 경우
2) Scaler 사용 시 Train 데이터로부터 Scaler를 fit 시키는 경우
3) Test 데이터에 대한 결측치 보간 시 Test 데이터의 통계 정보(평균, 최빈값 등)를 사용하는 경우
4) 파생변수를 생성할 시 2개 이상의 Test 데이터들의 정보를 활용할 경우
📌참고링크 : https://www.kaggle.com/code/alexisbcook/data-leakage
Stratify( 층화 표집 )
✅ train_test_split (Stratify)
📝 train과 test 데이터에 클래스 비율을 동일하게 분리
📝 train_test split에서 사용하는 파라미터로
📝stratify값을 target 값으로 지정 => target의 class 비율을 유지 한 채로 데이터 셋을 split
=> 만약 이 옵션을 지정해주지 않고 classification 문제를 다룬다면, 성능의 차이가 많이 남
sklearn.model_selection.StratifiedKFold
Examples using sklearn.model_selection.StratifiedKFold: Recursive feature elimination with cross-validation Recursive feature elimination with cross-validation GMM covariances GMM covariances Recei...
scikit-learn.org
✅ train_test_split 파라미터
1) train_test_split() arrays : 분할시킬 데이터
2) test_size: 테스트 셋의 비율, default = 0.25
3) train_size: 학습 데이터 셋의 비율, defalut = 1-test_size
4) random_state : 고정할 seed값
5) shuffle: 기존 데이터를 나누기 전에 순서를 섞을것인지, default = True
6) stratify: 지정한 데이터의 비율을 유지한다. 분류 문제의 경우 해당 옵션이 성능에 영향을 끼친다
Random_Forest (랜덤 포레스트)
✅랜덤 포레스트(영어: random forest)
📝 분류, 회귀 분석 등에 사용되는 앙상블 학습 방법의 일종
=> 훈련 과정에서 구성한 다수의 결정 트리로부터 부류(분류) 또는 평균 예측치(회귀 분석)를 출력함으로써 동작
✅ Decision Tree의 단점을 극복하기 위함
📝 DecisionTree의 단점
- Overfitting 문제: Decision tree는 학습 데이터에 과도하게 학습할 수 있어서, 과적합(overfitting)이 발생하기 쉽습니다. 이러한 문제를 해결하기 위해 pruning 등의 기법이 사용됩니다.
- 결정 경계의 수직/수평선 문제: Decision tree는 분류 경계를 수직 또는 수평선으로만 설정하기 때문에, 데이터가 대각선 방향으로 구분되는 경우 결정 경계를 잘 파악하지 못할 수 있습니다.
- 불균형 데이터셋 처리 문제: Decision tree는 불균형한 데이터셋에서 성능이 저하될 수 있습니다. 이는 일부 클래스에 대한 샘플이 다른 클래스보다 매우 적은 경우에 특히 더 큰 문제가 됩니다.
- 연속형 변수 처리 문제: Decision tree는 연속형 변수를 처리하기에 적합하지 않습니다. 일반적으로 연속형 변수를 범주형 변수로 변환한 후에 사용해야 합니다.
- Robustness 문제: Decision tree는 데이터의 작은 변화에도 결과가 크게 변할 수 있습니다. 따라서, 노이즈가 있는 데이터나 이상치(outlier)가 있는 데이터에서 성능이 저하될 수 있습니다.
✅ 의사결정나무 (회귀)
📝결정 트리 중 목표 변수가 연속하는 값, 일반적으로 실수를 가지는 경우 회귀 트리라 한다.
🤔 랜덤포레스트의 트리의 개수?
📝 적절한 트리의 개수를 찾으려면
1)교차 검증(cross-validation) 2)그리드 서치(grid search)
1)교차 검증을 통해 모델의 일반화 능력을 평가
2)그리드 서치를 통해 다양한 *하이퍼파라미터를 조합
=> 최적의 모델
📌하이퍼 파라미터

💡교차 검증(cross-validation) : 테스트 데이터를 제외한 무작위로 중복되어 있지 않은 k개의 데이터로 분할 (k-1) 개는 학습 데이터로 사용 나머지 1개의 데이터를 검증 데이터로 사용].
💡 그리드 서치(grid search) : 하이퍼 파라미터가 가능한 모든 조합을 시도하여 최적의 파라미터 값을 찾는 방법
💡 파라미터: 데이터 학습을 통해 자동으로 그 값을 결정
💡 하이퍼 파라미터 : 사용자가 경험적으로 그 값을 결정
📊 챗 GPT가 생각한 적절한 랜덤포레스트의 트리 개수

📌 Decision Tree(결정나무 학습법)
https://ko.wikipedia.org/wiki/%EA%B2%B0%EC%A0%95_%ED%8A%B8%EB%A6%AC_%ED%95%99%EC%8A%B5%EB%B2%95
DecisionTree
Decision Tree Depth
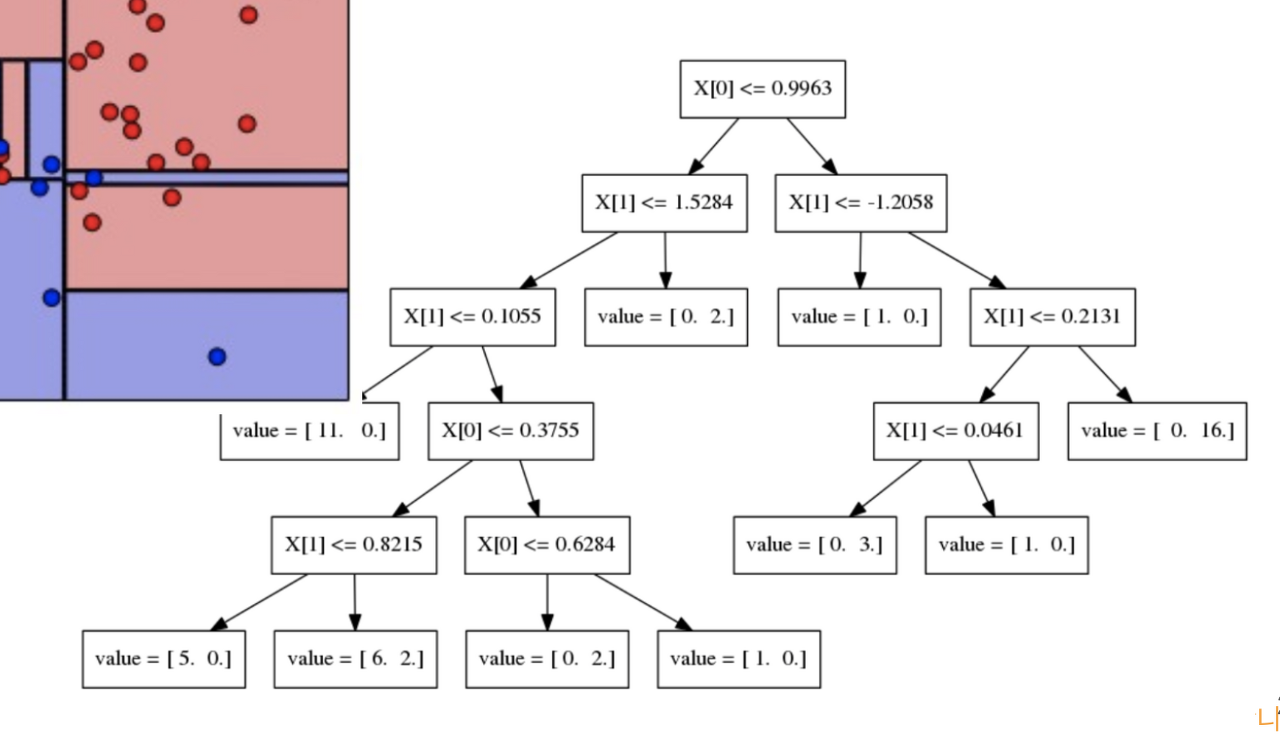
✅Max_depth의 해석
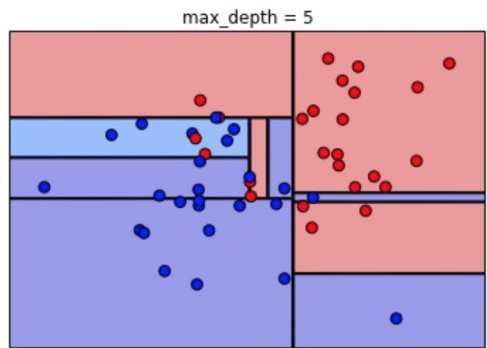
📝 루트노드 아래의 depth 의 수
✅ Depth 추론 방법 1)

✅ Depth 추론 방법 2)

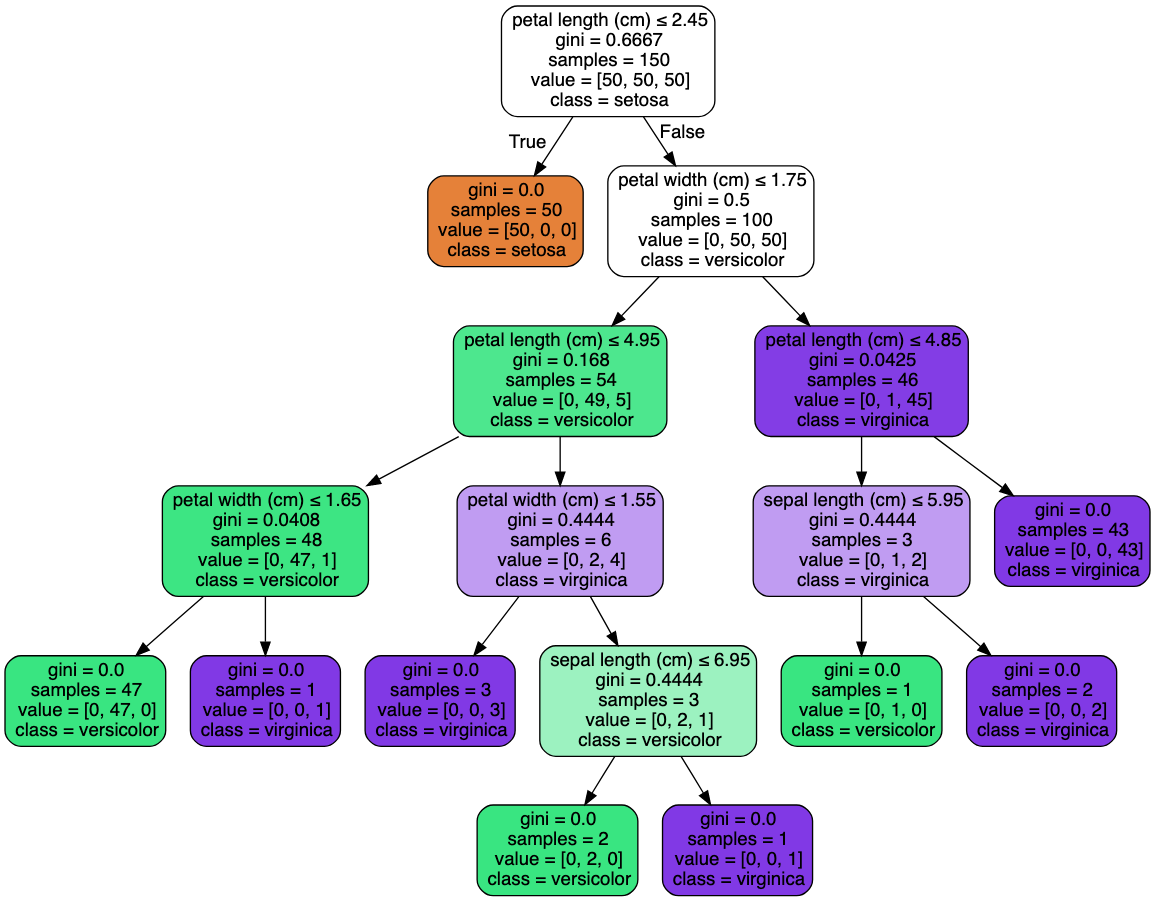
📝가지치기여부 및 계산의 복잡도 때문에 depth 정도를 세어보는 것까지 추천
=>depth 가 DecisionTree 에서는 성능에 가장 많은 영향
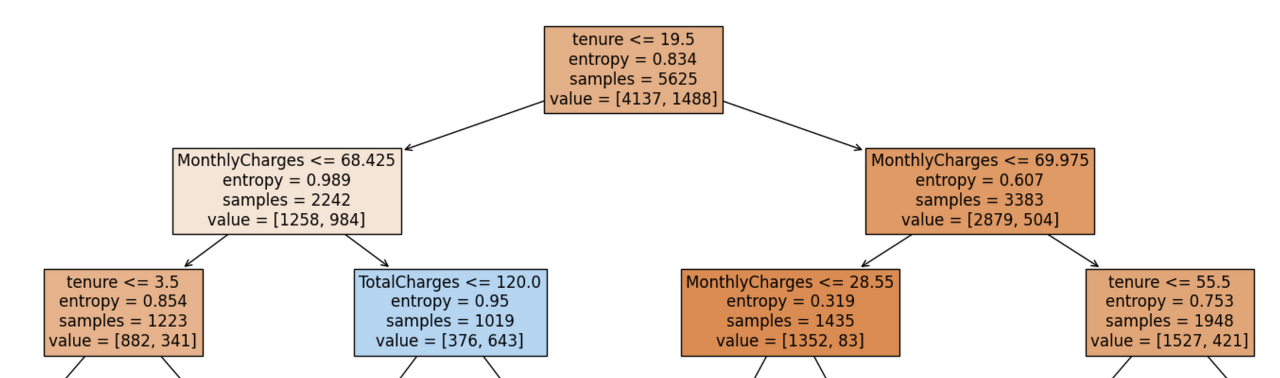
📝 박스에 자세한 설명 추가하려면
feature_names[1] 이렇게 어떤 피처에 해당하는지 알 수 있음
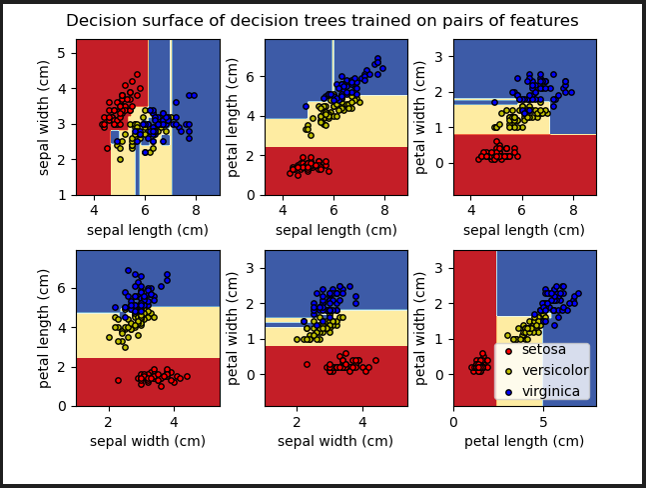
📝 Decision Tree 박스그림과 트리그림의 이해

연관분석
✅데이터 안에 존재하는 품목 간의 연관규칙(association rules)을 발견하는 과정
📝 두 가지 항목의 연관성을 통하여 한 항목의 값을 알 경우 다른 항목의 값을 예측해 내는 방법
✅ 연관분석 예시
📝지지도 - A와 B가 동시에 구매되는 거래의 비율
📝신뢰도 - A를 구매했을 때 B도 구매할 조건부 확률
📝향상도 - A를 구매했을 때 B를 구매 할 구매확률의 증가 비율

Bagging(Bootstrap Aggregating)
✅ 데이터 샘플링을 통해 모델을 학습시키고 결과를 집계하는 방법
✅ Bootstrap aggregating의 줄임말
📝통계적 분류와 회귀 분석에서 사용되는 기계 학습 알고리즘의 안정성과 정확도를 향상시키기 위해 고안된 일종의 앙상블 학습법의 메타 알고리즘
📝분산을 줄이고 과적합(overfitting)을 피함
=> 결정 트리 학습법이나 랜덤 포레스트에만 적용되는 것이 일반적,그 외의 다른 방법들과 함께 사용가능

✅ 신뢰구간을 구할 때 n_boot 라는 파라미터
📝 선거 때 출구조사와 비슷한 개념입니다. 전수조사를 하지 않고 샘플을 추출해서 분석하는 방법을 떠올려 보세요.
✅ 부트스트랩이란? (모델링 bootstrap 아님!)
📝모수의 분포를 신뢰구간으로 추정하는 아주 파워풀한 방법
데이터 홀릭 팟캐스트 링크
https://www.podbbang.com/channels/1771386
데이터홀릭
모두가 궁금해하는 데이터의 모든 것을 알려드립니다.데이터에 미쳐있는 사람들과 함께하는 데이터홀릭! 지금 시작합니다!
www.podbbang.com
'Python > ▶ 머신러닝' 카테고리의 다른 글
| 8주차 TIL ( Clustering / 상관관계 ) (0) | 2023.03.07 |
|---|
