728x90
Pandas 기초
1) Pandas 라이브러리 도입
# 필요한 라이브러리를 로드합니다.
# pandas, numpy를 불러옵니다.
import pandas as pd
import numpy as np2) 데이터 프레임 생성
# 비어있는 데이터프레임을 생성합니다.
df = pd.DataFrame()
df3) 컬럼 추가하기
①약품명 칼럼:
더보기

데이터 프레임 형태
# 약품명 시리즈 타입으로 약품명을 만듭니다.
# 다음의 리스트를 만들고 약품명이라는 컬럼에 담습니다.
df["약품명"] = ["소화제", "감기약", "비타민", "digestive", "Omega3", "오메가3", "vitamin", "Vitamin"]
df
②가격 칼럼:
더보기

데이터 프레임 형태
# 가격 컬럼을 만듭니다.
# df["가격"] 이라는 컬럼에 3500 이라는 값을 넣습니다.
# 그리고 컬럼이 제대로 추가 되었는지 데이터 프레임 전체를 출력해 봅니다.
# 데이터프레임, 행렬, 2차원
df["가격"] = 3500
df
③한 줄의 칼럼만 보고 싶을 때:
더보기
# 가격 컬럼만 가져와서 봅니다.
# 컬럼 하나만 가져오면 데이터프레임 전체를 출력했을 때와 다른 모습을 보입니다.
# 이렇게 데이터를 가져오면 Series 라는 데이터 형태로 출력이 됩니다.
# Seies, 벡터, 1차원
df["가격"]0 3500
1 3500
2 3500
3 3500
4 3500
5 3500
6 3500
7 3500
Name: 가격, dtype: int64# type 을 사용해서 데이터의 타입을 출력할 수 있습니다.
type(df["가격"])
-------------------------------------------------
pandas.core.series.Series# type 을 사용해서 데이터의 타입을 출력할 수 있습니다.
type(df["약품명"])
------------------------------------------------
pandas.core.series.Series
4) 컬럼값 변경하기
①가격 컬럼 값 변경:
더보기
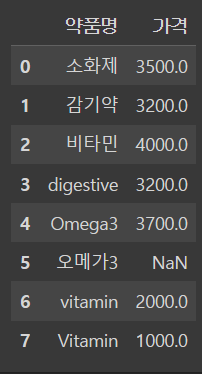
# 가격을 다음의 리스트 값으로 변경합니다.
price = [3500, 3200, 4000, 3200, 3700, np.nan, 2000, 1000]
df["가격"] = price
df
------------------------------------------------------------
②nan, null 값 :
더보기
# nan == not a number 의 약자로 결측치를 의미합니다.
# null 값 : 데이터베이스에서 없는 값을 의미 . 넘파이에서는 nan으로 결측치 표시
# nan의 데이터 타입은 float 입니다.
type(np.nan)
type(df["가격"])pd.Series([1, 2, 3])
---------------------
0 1
1 2
2 3
dtype: int64pd.Series([1, 2.0, 3])
----------------------
0 1.0
1 2.0
2 3.0
dtype: float64pd.Series([1, np.nan, 3])
--------------------------
0 1.0
1 NaN
2 3.0
dtype: float64pd.Series([1, 2, 3, np.nan, "문자"])
-------------------------------------
0 1
1 2
2 3
3 NaN
4 문자
dtype: object
③ '지역' 컬럼 추가:
더보기
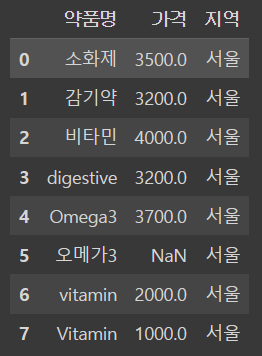
# "지역" 컬럼을 하나 더 추가해 봅니다.
df["지역"] = '서울'
df
④ '종류' 컬럼 추가:
더보기

# "종류"라는 컬럼을 만들어 일반의약품이라는 내용을 추가해 봅니다.
df["종류"] = '일반의약품'
df
⑤실수로 칼럼을 잘못 추가했거나 삭제하고자 할 때:
더보기
# axis 0:행, 1:컬럼을 의미합니다.
# inplace 기능보다는 해당 변수에 다시 할당해서 사용하는 것을 권장합니다.
# inplace 를 사용하면 method chaining 을 했을 때 동작하지 않는 문제가 있습니다.
df["종류2"] = "전문의약품"
# df.drop(columns="종류2") ----이 방법만 사용하면 안 없어질 수도 있음. df를 새로 명명해주어야함
df = df.drop(labels="종류2", axis=1) -------이 방법처럼 df 객체에 다시 저장해주어야함
df
#inspect : 판다스가 아닌 웹페이지의 소스코드 보기
#? => help 도움말(= help(df.drop))
#?? => 소스코드 보기
#Shift + tab => Jupyter에서 사용하는 단축키5)데이터 요약하기
① 데이터 프레임의 정보 (df.info( )):
더보기
# 데이터 프레임의 정보를 봅니다.
df.info()
--------------------------------
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 8 entries, 0 to 7
Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 약품명 8 non-null object
1 가격 7 non-null float64
2 지역 8 non-null object
3 종류 8 non-null object
dtypes: float64(1), object(3)
memory usage: 384.0+ bytes
② 데이터 프레임의 크기(df.shape( )):
더보기
# 데이터 프레임의 크기를 출력합니다.
# (행, 열)
df.shape
----------------------------------
(8, 4)
③ 데이터의 타입만(df.dytpes):
더보기
# 데이터의 타입만 봅니다.
df.dtypes
------------------------
약품명 object
가격 float64
지역 object
종류 object
dtype: object
※ 함수 사용할 때 :
더보기
# 함수 사용할 때
# 소괄호 있음 : method (데이터 입력 불필요) / 소괄호 없음 : property -> attribute 타입
④ 데이터 프레임의 요약정보(df.describe()):
더보기

# 데이터프레임의 요약정보를 가져옵니다.
# 수치형 데이터의 기술통계 값을 봅니다.
# 'count'=> 결측치를 제외한 빈도수,
# 'mean'=> 평균,
# 'std' => 표준편차,
# 'min' => 최솟값,
# IQR : '25%', '50%', '75%', => 값을 순차정렬 했을 때 앞에서부터 25%, 50%, 75% 위치에 있는 값
# => 사분위수, 1사분위수, 2사분위수(=중앙값, =중간값, =median), 3사분위수
# 'max' => 최댓값
df.describe()
⑤ 범주형 데이터의 기술통계 값:
더보기
# 범주형 데이터의 기술통계 값을 봅니다.
# df.describe(include ='object')
# 'count' => 결측치를 제외한 빈도수,
# 'unique' => 유일값,
# 'top' => 최빈값(mode), 'freq' => 최빈값의 빈도수
df.describe(include= "O")
----------------------------------------------
6) 컬럼명으로 데이터 가져오기
① 컬럼 1개의 데이터 가져오기 :
더보기
df['약품명']
--------------
0 소화제
1 감기약
2 비타민
3 digestive
4 Omega3
5 오메가3
6 vitamin
7 Vitamin
Name: 약품명, dtype: object
df['가격']
------------
0 3500.0
1 3200.0
2 4000.0
3 3200.0
4 3700.0
5 NaN
6 2000.0
7 1000.0
Name: 가격, dtype: float64
② 컬럼 2개이상의 데이터 가져오기 :
더보기
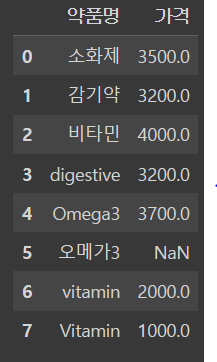
#파이썬에서 2개 이상의 데이터를 다룰 때는 보통 리스트 자료형을 사용합니다.
#리스트는 대괄호[ ]로 묶여져 있는 데이터를 의미합니다.
df[['약품명', '가격']]
#데이터에 대괄호를 한 번 더 씌워주면 데이터프레임형태로 변환 가능
-------------------------------------------------------------------
③ 행 기준으로 데이터 가져오기 :
더보기
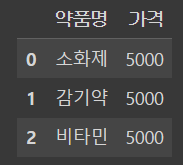
# 인덱스 번호로 첫번째 데이터 가져오기
df.loc[0]
---------------------------------
약품명 소화제
가격 5000
Name: 0, dtype: object
# 인덱스 번호로 위에서 세번째까지 데이터 가져오기
df.loc[[0, 1, 2]]
③ 행과 열 데이터 함께 가져오기 : 의문점 포함
더보기
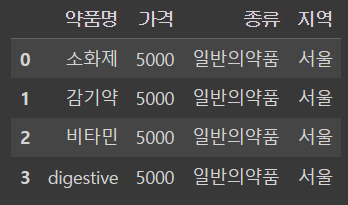
# loc의 경우 행이나 컬럼의 Label을 기준으로 하고
# iloc의 경우 인덱스 값을 기준으로 하기 때문에 서로 사용하는 방식이 다르다
[출처] 파이썬 기초(3) - 데이터 인덱싱/조건추출(loc/iloc)|작성자 삼삼삼
#컬럼명에 특수문자, 띄어쓰기 등이 들어갈 때,
#메서드, 프로퍼티, 어트리뷰트 명과 동일할 때
# loc[행, 열]
df.loc[0,'약품명']
# .loc => 인덱스, 컬럼명으로 가져옵니다.
df.loc[[0, 1, 2], ['약품명', '가격']]
# 행,열 슬라이싱도 가능
df.loc[:3, : '지역']
# 수업시간에 배울 때는 추출하고자하는 데이터 행까지 포함하는걸로 배웠는데.. (리스트나 다른 마스킹과 다르게)
어떻게 된거지...흠.....
마지막으로 첫 4개 행의 데이터를 추출해보자 (0~3번 행인덱스)
위와 같이 일일이 행을 지정해줘도 되지만 더 간단한 방법이 있다
바로 :을 이용하는 것이다
summer.iloc[0:4]
주의할 점은 0~3번 행인덱스를 지정하려면 [0: 3]이 아니라 [0: 4]를 입력해야 한다는 것이다
a:b에서 a는 포함되고, b는 포함되지 않는다(b-1까지의 인덱스가 포함된다)
[출처] [판다스] iloc로 원하는 데이터 추출하기|작성자 기록하는개발자
※ at, iat 와 쿼리
더보기
#at, iat
# at, iat 는 single value 가져올 때 사용하는데 수업에서는 사용하지 않을 예정입니다.
# => 앞으로 판다스에서 없어질 예정입니다.
#query
# 수업에서는 쿼리 기능은 사용하지 않을 예정이에요.
# boolean Indexing 을 사용하면 같은 기능입니다.
# 컬럼명에 특수문자, 띄어쓰기 등이 들어가면 쿼리를 쓰다 오류가 발생했을 때 찾기가 어렵습니다.
# 그래서 권장하지 않습니다.
④ 특정약품만 가져오기:
더보기

# 파이썬의 정규표현식에서는 |는 or를 &는 and를 의미합니다.
# 여러 검색어로 검색을 한다 가정하고 | 로 검색어를 넣어준다고 생각하면 됩니다.
# str.contains 를 사용해서 약품명을 가져올 수 있습니다.
#데이터프레임 컬럼에서 특정 문자열을 검색할 때는 str.contains()
df['약품명'] == '비타민
df['약품명'].str.conntains('비타| vita')
--------------------------------------------------------------------------
0 False
1 False
2 True
3 False
4 False
5 False
6 False
7 False
Name: 약품명, dtype: bool# 약품명을 모두 소문자로 변경
df['약품명_소문자'] = df['약품명'].str.lower()
df
# 약품명_소문자 컬럼에서 "vita|비타" 값이 들어가는 문자를 찾습니다.
df[df["약품명_소문자"].str.contains('vita|비타')]
#df[ ] 안해주면 df["약품명_소문자"].str.contains('vita|비타') 값은 True/False만 반환
#df[ ] 해주어야 포함된 데이터가 데이터프레임형태로 나옴
7) 가격이 특정 금액 이상, 이하인 데이터 찾기
더보기

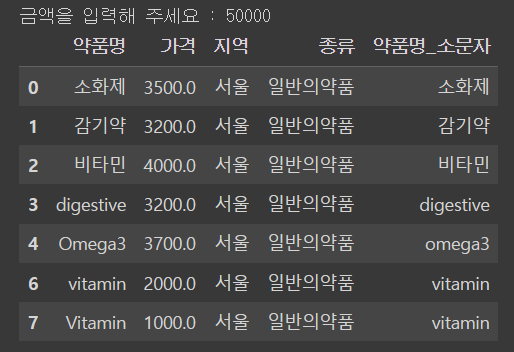
# 특정 금액 이상의 가격에 해당되는 데이터프레임을 가져옵니다.
df[df['가격'] > 3500]# 특정 금액 이하의 가격에 해당되는 데이터프레임을 가져옵니다.
random_nomey = int(input('금액을 입력해 주세요 : '))
df[df['가격'] <= random_money]
8) 정렬하기
더보기

# sort_values 를 통해 정렬합니다.
df.sort_values( by=['약품명_소문자', '가격'], ascending[False, True])
9) 파일로 저장하기
더보기

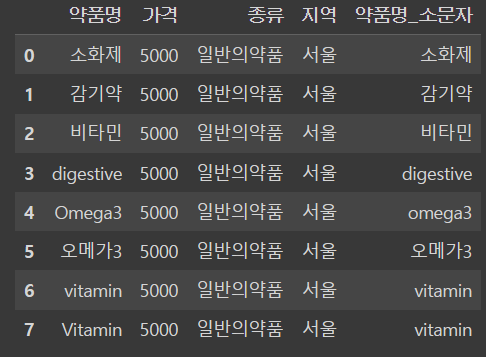
# to_csv 를 통해 csv 파일로 저장합니다.
df.to_excel('pandas_example.xlsx', encoding='cp949')
#encoding = 'cp949'는 저장할 때 한글 깨지는것 방지
# 저장된 csv 파일을 읽어옵니다.
pd.read_excel('pandas_example.xlsx')
# Unnamed : 데이터 프레임 만들 때 생성되는 인덱스, 미 입력시 자동으로 부여
# Unnamed 없애주기 위해선 저장 시 # index = False 추가
df.to_excel('pandas_example.xlsx', encoding='cp949', index = False)
728x90
'Python > ▶ Python & Pandas' 카테고리의 다른 글
| 5주차 plotly (1) | 2023.02.05 |
|---|---|
| 5주차 TIL ( Pandas : 시각화 ) (0) | 2023.01.31 |
| 4주차 WIL (1) | 2023.01.19 |
| TIL ②일차 (0) | 2023.01.11 |
| TIL ①-2일차 (0) | 2023.01.10 |


