📝 실습코드 다시 쳐보면서 막혔거나 기억해야할 것 위주로 📝
💡모든 함수의 모든 기능과 아규먼트를 외울 수 없으니 문서 보는것(Shift + Tab)을 습관화하자 📝
1. 데이터 타입의 변경
'분양가격' 컬럼( 결측치 섞여있음 )
object => int or float
# 결측치가 섞여있으면 변환이 제대로 이루어지지 않음.
pd.to_numeric(df_last['분양가격'], errors = 'coerce' )
numeric의 docstring을 보니
errors = coerce를 입력해주게 되면 유효하지 않은 문장분석은 전부 NaN(결측값)으로 전환
+
# df_last['분양가격'].replace(' ', np.nan).astype(float)
#' ' 비어있는 값 있어서 숫자로 바꿔주지 못함이 방법도 말씀해주셨는데 replace 부분에서 np.nan으로 해주는 이유를 잘 모르겠다.
df_last['분양가격'] = pd.to_numeric(df_last['분양가격'], errors = 'coerce' )
df_last['분양가격']df_last['분양가격']에 나온 값 할당 해주기 . 하지 않으면 다시 리셋된 값(object) 나옴
2. Replace ❗❗❗
replace와 str.replace의 차이
# replace => 데이터프레임에만 사용가능
(regex=True 를 지정하지 않으면 완전히 일치하는 데이터에 대해서면 변경)
# str.replace => 시리즈에만 사용가능
(일부만 일치해도 변경)❗ 메서드명이 같더라도 python string 의 메서드인지, pandas 의 데이터프레임의 메서드인지 등에 따라 다르게 동작
+unique
# 데이터를 수집할 때 텍스트가 많이 들어가게 되면 용량 그만큼 증가
# 공개되는 대용량 데이터 보면 텍스트데이터가 코드로 되어있는 경우가 많음.
# 데이터의 용량이 크면 로드도 오래걸리지만 전처리나 연산에서의 속도도 오래걸림.
# 관리,속도 이슈로 보통은 수치형태의 코드값으로 관리
# 규모구분의 unique 값 보기
df_last['규모구분'].unique()
코드를 텍스트 대신 수치로 하는 이유 ❗
✅데이터 전처리의 효율성
✅연산에서의 속도
✅관리 및 유지보수 용이
=> 코드를 수치형태 값으로 관리
3. Pariplot
- pairplot => 여러개의 수치형 변수를 짝 지어 표현하기에 적합
- seaborn 서브플롯에서는 figure가 동작 X
# pairplot
# height =2.5, aspect = 1 로 상대값 지정해서 조정
# corner=True 하는 이유 :대각선으로 마주보는 값은 같은 값이기 때문에 대각선 위 제외하고 볼 수 있음
# hue : 데이터프레임내 컬럼명으로 지정. 플롯의 측면을 다른 색상으로 매핑하기 위함.sns.pairplot(df_last, hue ='지역명',height=2.5, aspect=1)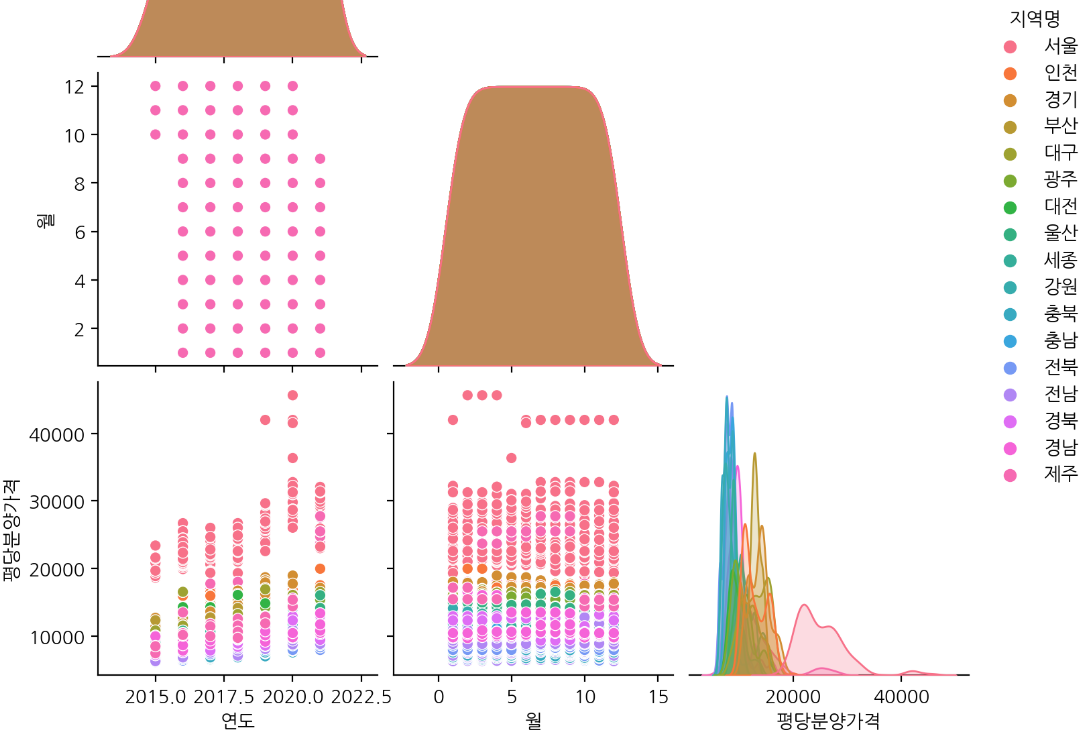
4. 모든 컬럼이 출력되게 설정
- pd.options.display.max_columns
pd.options.display.max_columns = None
# 컬럼이나 행이 너무 많은데 None으로 설정하면 display 하는데 시간 오래걸림
# 너무 큰 데이터에 이 기능 사용하면 노트북이 느려질 수 있기 때문에 주의 !
5. '연도', '월' 파생변수 생성
- string Accessor
# string Accessor
df_first_melt['연도'] = df_first_melt['기간'].str.split('년',expand=True)[0].astype(int)
df_first_melt['월'] = df_first_melt['기간'].str.split('년',expand=True)[1].str.replace('월','').astype(int)
df_first_melt.head(2)
#expand = True => 분할된 문자열을 데이터프레임의 열(컬럼)로 확장
6. melt로 Tidy data 만들기
- ✅ Tidy data: 깔끔한 데이터 (정리가 잘 되어 있는 것과는 다름❗ )
- ✅ 깔끔하지 않은 데이터 (한 열에 하나의 변수 있는 게 아니라 다양한 열에 하나의 변수가 분포되어있음)
- ✅ pd.melt() 열에 있던 데이터를 행으로 녹여내린다

# pd.melt 를 사용하며, 녹인 데이터는 df_first_melt 변수에 담습니다.
df_first_melt = pd.melt(df_first, id_vars='지역') #id_vars = 기준이 되는 컬럼
df_first_melt
7. df.groupby 와 pd.pivot_table
✅ groupby : pivot_table은 groupby를 사용하기 쉽게 한 번 더 추상화 해놓은 함수
1. 기본적인 연산,평균, 분산, 표준편차, 최댓값, 최솟값, 중앙값 등의 값을 연산
=> groupby를 쓰든 pivot_table을 쓰든 상관 X
2. 속도 : groupby > pivot_table
반환값 : pivot_table => 데이터프레임
반환값 : groupby는 컬럼이 series 형태라면 series 로 반환
3. pivot 은 데이터의 형태를 바꿀 때 사용
pivot : 연산 X
pivot_table :연산 O
지역별 평당분양가격
# df.groupby(["인덱스로 사용할 컬럼명"])["계산할 컬럼 값"].연산()
df.groupby(['지역명'])['평당분양가격'].mean().sort_values().plot(kind='bar',rot=0)지역, 연도별 평당분양가격
# 연도별, 지역별로 평당분양가격의 평균을 구합니다.
yprice = df.groupby(['연도','지역명'])['평당분양가격'].mean().unstack()
yprice.iloc[:5,:5]
melt의 반대개념인듯
✅ pivot_table
지역별 평당분양가격
# region_price = pd.pivot_table(data = df, index='지역명', values='평당분양가격')
region_price = df.pivot_table(index='지역명',values = '평당분양가격')
region_price
지역,연도별 평당분양가격
# 연도를 인덱스로, 지역명을 컬럼으로 평당분양가격을 피봇테이블로 그려봅니다.
# yrprice = pd.pivot_table(data='df', index='연도', columns='지역명', values='평당분양가격')
yrprice = df.pivot_table(index='연도', columns='지역명', values='평당분양가격')
yrprice
8. sns(seaborn) Heatmap
# 바뀐 행과 열을 히트맵으로 표현해 봅니다.
plt.figure(figsize=(12, 6))
sns.heatmap(yrprice.T, cmap="Blues", annot=True, fmt=",.0f")
#fmt => format 을 의미합니다.
# .0f 는 float을 소숫점 0번째 자리까지 표기한다는 의미입니다.
# , 는 천단위로 , 로 구분해서 표기해 달라는 의미입니다.
# ,.0f 는 천단위로 ,를 찍고 소숫점 0번째 자리까지 표기해 달라는 의미입니다.

❗ replace와 str.replace
# replace => 데이터프레임에만 사용가능
(regex=True 를 지정하지 않으면 완전히 일치하는 데이터에 대해서면 변경)
# str.replace => 시리즈에만 사용가능
(일부만 일치해도 변경)❗ groupby 와 pivot_table
groupby : pivot_table은 groupby를 사용하기 쉽게 한 번 더 추상화 해놓은 함수
1. 기본적인 연산,평균, 분산, 표준편차, 최댓값, 최솟값, 중앙값 등의 값을 연산
=> groupby를 쓰든 pivot_table을 쓰든 상관 X
2. 속도 : groupby > pivot_table
반환값 : pivot_table => 데이터프레임
반환값 : groupby는 컬럼이 series 형태라면 series 로 반환
3. pivot 은 데이터의 형태를 바꿀 때 사용
pivot : 연산 X
pivot_table :연산 O
pivot_table의 aggfunc 의 기본값은 평균(mean)❗ Tidy data
변수가 열이 되고 행이 관측치가 되는 데이터
'Python > ▶ Python & Pandas' 카테고리의 다른 글
| 6주차 Burger 지수 (0) | 2023.02.09 |
|---|---|
| 6주차 시각화(KOSIS의 산업별 통계) (0) | 2023.02.07 |
| 5주차 plotly (1) | 2023.02.05 |
| 5주차 TIL ( Pandas : 시각화 ) (0) | 2023.01.31 |
| 4주차 WIL (1) | 2023.01.19 |



