💡 Key World 정리 💡
✅
import 정도만 손을 봐도 트래픽비용이 줄어들 수고 있고, 캐시를 어떻게 사용하느냐, 파일 I/O 관리, 데이터베이스 관리 등에 따라 비용이 달라지게 됩니다.
=> 트래픽을 분석이나 관리해 주는 도구도 있습니다. 인프라에서 발생하는 로그 데이터를 따로 분석
✅
isin은 정확히 일치해야하기 때문에 !
=> str.contains
✅df_b.pivot_table
margin =>margins : bool, default False
Add all row / columns (e.g. for subtotal / grand totals).
열이나 행을 모두 더한다
✅pivot_table에서는 value값도 지정해주어야함 !!!!
✅heatmap() => 전체 스케일 비교에 적절
style.background_gradient() => 각 변수별 비교에 적절
✅style.background_gradient는 axis 옵션이 있어 전체 스케일 비교는 물론 변수별 비교가 가능합니다!🙂
https://pandas.pydata.org/docs/reference/api/pandas.io.formats.style.Styler.background_gradient.html
✅버거지수계산할 때 롯데리아(분모)가 0인경우
inf라는 값 발생❗
=> 제거 or 따로 수치 입력 ?
1)목적에 따라 다른데, 0으로 처리해도 되는 데이터라면 0으로채우면됨(0으로표시)
2) inf대신 np.nan으로도 변경(결측치로 표시)
근데 빈도수는 0으로 채우면 되는데 0이 안되는 데이터라면❓
=> 나이, BMI지수, 체중, 키
나이가 중요한 요소인데 나이에 결측치가 많은데 결측치가 있으면 머신러닝 모델이 계산X
나이 사용할 수 있는 방법❓
=> Binning ( 구간화 )
=> 어린이, 성인, 고령자 등으로 범주화 하는 것이 구간화의 일종
=> 시각화에서 히스토그램 그릴 때 사용
=> bin 용어는 히스토그램 시각화에서도 막대의 수를 구할 때 사용 보통 히스토그램을 시각화 할 때 결측치는 제외하고 시각화
💡
DB에서 설정할 때 없는 값은 null 로 관리 => 가끔 -1로표기.
-1 값으로 평균을 계산하면 완전 잘못된 계산
✅scatterplot을 여러도구에서 그려봄
수치 변수간의 상관 관계를 보고자 할 때 주로 시각화
어디서?
1) fdr에서 maang의 주가상승률 비교할 때 => 판다스 scatter matrix
2) 아파트 평당분양가격 => seaborn pairplot
3) px.scatter_matrix()
✅
mpg_corr = sns.load_dataset("mpg").corr(numeric_only=True)
mask = np.tril(np.ones_like(mpg_corr)) =>아래를 날림
mask = np.triu(np.ones_like(mpg_corr)) =>위를날림
✅ scatterplot() 은 두 수치형 변수간의 관계를 표현하기에 적합
✅ scatterplot은 수치형 변수를 표현하기에 적합합니다. 범주형 변수를 표현하게 되면 점이 겹쳐져서 빈도나 분포를 제대로 보기 어렵습니다.
✅ 1) 스토리지 절약(디스크공간) => parquet, 2) 메모리절약 => downcast,
✅ 3-2(전처리) / 상호명이 없는 데이터 제거
df['상호명'] = df['상호명'].dropna(axis=0, how='any')이 코드는 왜 안되는지 궁금.......
✅ 3-4 (전처리) / BMKL 추출
df_b = df[df['상호명_대문자'].str.contains('버거킹|BKR|맥도날드|맥도널드|롯데리아|케이에프씨|KFC')
& (df['상권업종대분류명'].isin(['음식', '소매', '생활서비스']))]각 두 조건
1) '상호명_대문자'가 burger 포함하는 경우
2) '상권업종대분류명'이 '음식', '소매', '생활서비스' 인 경우
설정은 잘해주었는데 df[ ]안에 두 조건이 다 들어가야한다!
계속 에러나서 시연파일 참고...
✅ 3-6(전처리) 브랜드명 파생변수 만들기
💡 방법 1 (loc)
df.loc(df_b['상호명_대문자'].str.contains('버거킹|BKR'), '브랜드') = '버거킹'
# df.loc(df_b['상호명_대문자'].str.contains('맥도날드|맥도널드'), '브랜드') = '맥도날드'
# df.loc(df_b['상호명_대문자'].str.contains('롯데리아'), '브랜드') = '롯데리아'
# df.loc(df_b['상호명_대문자'].str.contains('케이에프씨|KFC'), '브랜드') = 'KFC'조건에 맞는 행을 찾음과 동시에 '브랜드'라는 컬럼(파생변수)에 값 입력...
아직 이렇게까지는 바로바로 안 나오는거 같다..ㅎㅎ
데이터 전처리 하다보면 느끼는 것 중에 하나가
iloc, loc 잘 쓰면 진짜 유용한 것 같다 . 특히 loc
loc는 조건 지정해준 후에 열(컬럼) 찾을 수 있어서 자주 쓰이고 잘 쓰게 되면 편할 것 같다 . 마스터하자..!
💡 방법 2 (for 문)
# for bname in burger :
bmkl = {'버거킹' : '버거킹|BKR',
'맥도날드' : '맥도날드|맥도널드',
'롯데리아' : '롯데리아',
'KFC' : 'KFC|케이에프씨'}
for brand, val in bmkl.items():
df_b.loc[df_b['상호명_대문자'].str.contains(val), '브랜드'] = brand
✅ 3-8(전처리) 전국/시도별 상호수와 버거지수
💡 방법 1 (crosstab/margin 기능 사용)
# crosstab -1
df_skorea = pd.crosstab(df_b['시도명'], df_b['브랜드'],
margins=True, margins_name='합계')📌 margins : 각 행과 각 열의 값들을 모두 더하여 출력
💡 방법 1-2 (crosstab/ .sum() 기능 사용)
# crosstab -2
df_skorea = pd.crosstab(df_b['시도명'], df_b['브랜드'])
df_skorea['합계'] = df_skorea.sum(axis=1)📌 aggfunc기능이 있긴한데 굳이 쓸 필요 없다. crosstab만 해준 값과 똑같고 , 값만 오히려 float 형태로 변환됨
💡 방법 2 (pivot_table 기능 사용)
# pivot_table
df_b.pivot_table(index='시도명', columns='브랜드', fill_value=0, values='상호명', aggfunc='count',
margins=True, margins_name='합계')📌 개인적으로 pivot_table이 조금 더 하이인터페이스라서 직관적이긴한데 value, aggfunc도 지정해주어야하고
index, columns에 각각 데이터 할당해야해서 crosstab이 조금 더 나은 것 같다
📌 fill_value : (집계 이후에) 결측값을 대체할 값 입력
💡 방법 3 (groupby 기능 사용)
# groupby
df_skorea = df_b.groupby(['시도명','브랜드'])['상호명'].count().unstack().fillna(0).astype('int')
df_skorea['합계'] = df_skorea.sum(axis=1)📌 unstack() : melt()의 반대개념

상기이미지와 같이
1번 인덱스(시도명) 값 하나에
2번 인덱스(브랜드) 값 여러개가 들어있는 경우
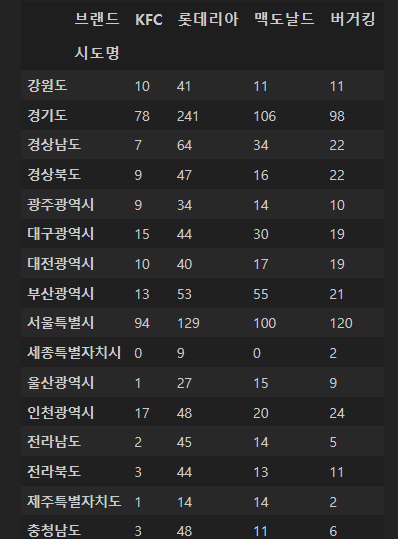
2번 인덱스의 값을 열(컬럼)으로 올린다.
✅ 3-9(전처리) 시도별 위도/경도 평균값
df_b.groupby(['시도명']).agg({'위도' : 'mean', '경도':'mean'})내가 한방법과 다른 방법도 있어서 참고용으로
✅ 3-10(전처리) 시군구별 상호수
#pivot_table
df_dist_count = df_b.pivot_table(index=['시도명', '시군구명'], columns='브랜드', values='상호명', aggfunc='count',
fill_value=0, margins=True, margins_name='합계')# groupby
df_dist_count = df_b.groupby(["시도명", "시군구명", "브랜드"]
)["상호명"].count().unstack().fillna(0).astype(int)📌이 챕터의 포인트는 시도명으로 한 번 그룹화하고 시군구별로 두 번 그룹화 해줘야한다는것
📌 pivot_table 과 groupby방식 차이점
1) groupby는 다음 줄에 따로 합계 코드를 쳐주어야한다
2) groupby는 따로 astype(int)를 해주어야한다
효율 pivot_table > groupby ? 일단 다 익숙하게 다룰 줄 알아야 할 것 같다.
✅ Mask
# mpg : mile per gallon 미국의 자동차연비 관련 데이터셋
# 실린더수, 마력, 무게, 엑셀 등의 수치와 자동차 연비의 상관관계 나타냄
# 마력(horsepower)과 무게(weight) 는 양의 상관
# numeric_only : float, int, boolean값만 받아옴
mpg_corr = sns.load_dataset("mpg").corr(numeric_only=True)
mask = np.tril(np.ones_like(mpg_corr))
sns.heatmap(mpg_corr, annot=True, cmap="seismic", vmin=-1, vmax=1, mask=mask)
📌 mask
히트맵 등 변수간 상관관계 보여주는 시각화 그래프에서 대각선 기준 위/아래로 마스킹할 부분 지정
(대각선 기준으로 위 아래는 같은 값이므로)
📌 np.tril(np.ones_like(mpg_corr))
tril : 아래/왼쪽 삼각형 날림 => 위/오른쪽 삼각형만 살림
📌 np.triu(np.ones_like(mpg_corr))
triu : 위/오른쪽 삼각형 날림 => 아래/왼쪽 삼각형만 살림
📌sns.pairplot & sns.heatmap
pairplot => 코너 제거 ( corner=True)
heatmap => (mask = mask)
mask
mask = np.tril(np.ones_like(mpg_corr))
✅ Diverging color
📌 sns.heatmap
diverging한 color => 색깔도 중요하다
📌 vmin = -1, vmax = 1로 설정하여 양의상관관계와 음의 상관관계 잘 나타내게 하는것이 좋음
'Python > ▶ Python & Pandas' 카테고리의 다른 글
| 8주차 WIL (Online_Retail 실습 복습) (0) | 2023.03.02 |
|---|---|
| 8주차 비즈니스 데이터 분석 (0) | 2023.02.28 |
| 6주차 시각화(KOSIS의 산업별 통계) (0) | 2023.02.07 |
| 6주차 Seaborn (0) | 2023.02.06 |
| 5주차 plotly (1) | 2023.02.05 |



