👨💼 SaaS 대시보드 템플릿
✅ 오거닉(Organic) : 자연유입
✅ 취소율(Churn rate) : 이탈률
💡 서비스(비즈니스)의 특징에 따라 봐야하는 지표가 다름!
비즈니스마다 유입인원수가 중요한지 이탈률이 중요한지가 달라짐
회원가입에 집중? 돈을 쓰는 고객에 집중? 신규 고객 유치에 집중?
광고, 프로모션, 오프라인 행사 등 여러가지 마케팅을 실시
구독형 서비스 같은 경우는 이탈률이 굉장한 지표
✅ 오아시스 쇼핑몰(마켓컬리와 비슷)
시작 : 슈퍼마캣 => 현재 : 유기농 식자재를 싼 가격에 매입(상장 논의중)
👨💼 CAC, CPA, CPL
CAC(Customer Acquisition Cost) : 고객 확보 비용
CPA(Cost Per Acquisition) : 확보 고객당 비용
CPL(Cost Per Lead) : 플랫폼 별 확보 고객당 비용

👨💼 ARPU & ARPPU
✅ARPU(Average Revenue Per User)
=> 앱 사용자 1인당 평균 결제 금액 = 매출 / 중복을 제외한 순수 활동 사용자 수
✅ARPPU(Average Revenue Per Paying User)
=> 유료 사용자 1인당 평균 결제 금액 = 매출 / 중복을 제외한 순수 유료 사용자 수
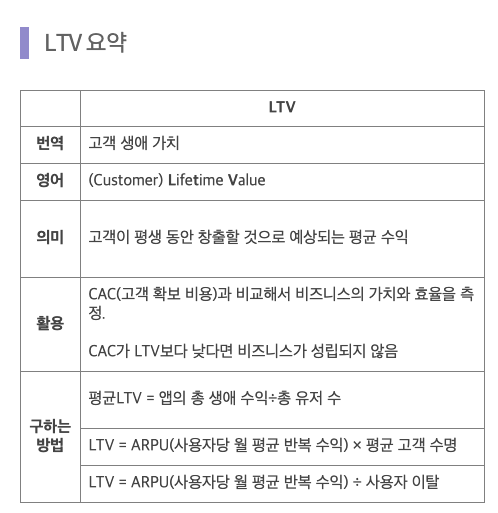
👨💼 LTV
LTV (LifeTime Value) : 고객 생애 가치
출처 링크 ▼
👨💼 머신러닝의 업종 별 활용
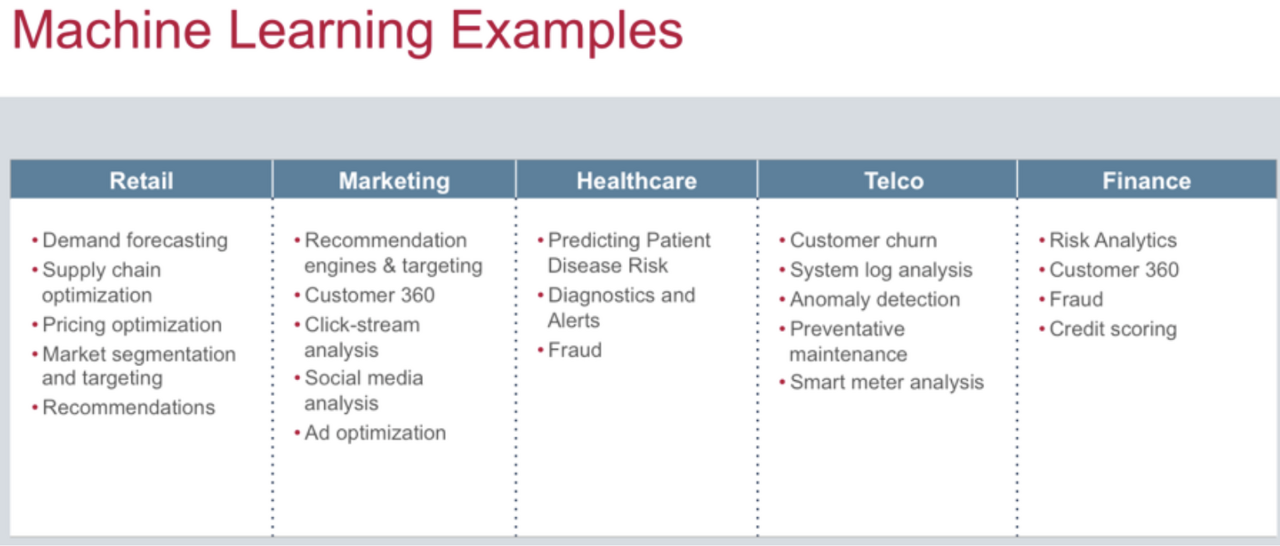
👨💼 소매, 리테일 서비스에 머신러닝을 어떻게 활용할 수 있을까❓
✅고객 분석
- 고객 데이터를 수집하고 분석하여 구매 패턴, 구매 선호도, 구매력 등을 파악합니다.
- 머신러닝을 활용하여 고객 데이터를 분석하면 고객의 취향과 관심사에 대한 인사이트를 얻을 수 있으며, 이를 기반으로 개별 고객에게 맞춤형 서비스를 제공할 수 있습니다.
✅재고 관리
- 머신러닝을 활용하여 소매업체는 과거 판매 이력, 계절성 및 트렌드 등을 고려하여 재고를 관리합니다.
- 머신러닝 모델은 판매 이력을 분석하고, 트렌드를 파악하여 재고 수준을 최적화하고 재고 부족 현상을 예측합니다.
✅가격 설정
- 머신러닝을 활용하여 경쟁 업체의 가격 변화를 모니터링하고, 이를 기반으로 자동으로 가격을 조정한다.
✅추천 시스템
- 머신러닝을 활용하여 추천 시스템을 구축할 수 있습니다.
- 고객 구매 이력과 관련 상품, 구매 내역, 구매 인기도 등을 고려하여 개별 고객에게 맞춤형 상품을 추천할 수 있습니다.
-> 고객 만족도와 매출 증대에 기여
✅사기 탐지
- 머신러닝을 활용하여 이상 거래를 탐지할 수 있습니다.
- 머신러닝 모델은 고객 구매 이력과 관련 데이터를 분석하여 이상 거래를 탐지하고, 대응 조치를 취할 수 있습니다.
👨💼 코호트 , 잔존률 분석
📝코호트 : 집단을 분리 ( ex 코호트 격리 : 집단을 나누어 격리시킴 )
✅ 앱 가입 날짜, 첫 구매 월, 위치, 획득 채널(유기 사용자, 공연 마케팅에서 오는 것 등) 등
공통점을 공유하는 사람들의 그룹 => 시간 경과에 따라 추적
몇 가지 일반적인 패턴 또는 행동을 식별하는 분석 방법.
✅ 리텐션 분석 : 같은 기간에 앱 설치를 경험한 사용자 그룹 => 시간지남에 따라 앱의 꾸준한 사용 여부(Retention)를 분석
👨💼 코호트 분석 : AARRR
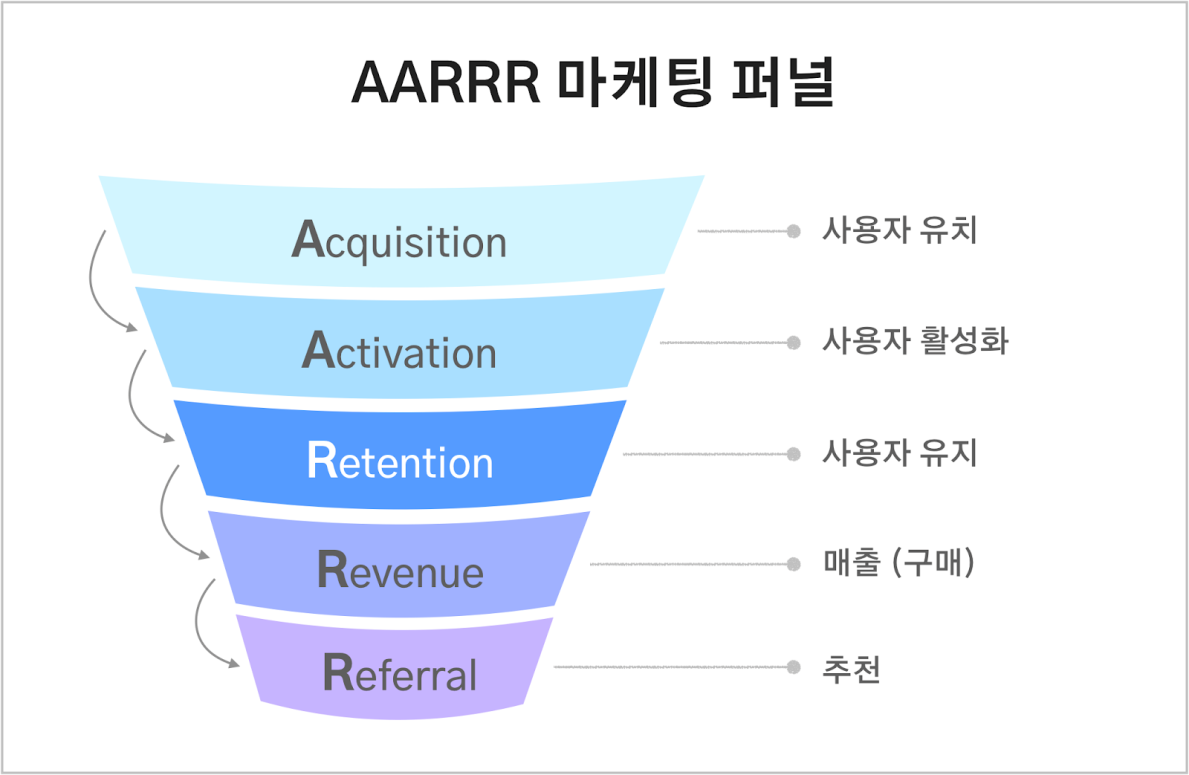
✅ 시장 진입 단계에 맞는 특정 지표를 기준으로 우리 서비스 상태를 가늠할 수 있는 효율적 기준
✅ 수많은 데이터 중 현 시점에서 가장 핵심적인 지표에 집중가능
✅ 분석할 리소스가 충분하지 않은 스타트 기업 등에게 매력적인 프레임워크
A => Acquisition : 사용자 유치
A => Activation : 사용자 활성화
A => Retention : 사용자 유지
R => Revenue : 매출(구매)
R => Referral : 추천
👨💼 Online_Retail (EDA) 파헤치기
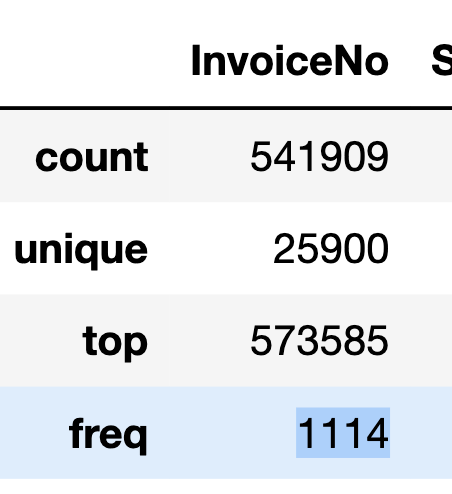
✅Top : InvoiceNo '573585' 의 개수가 가장 많다!
✅Freq : InvoiceNo '573585'가 1114번 !

✅unique : 전체 주문은 54만건이지만 유니크한 주문건은 2.5만개
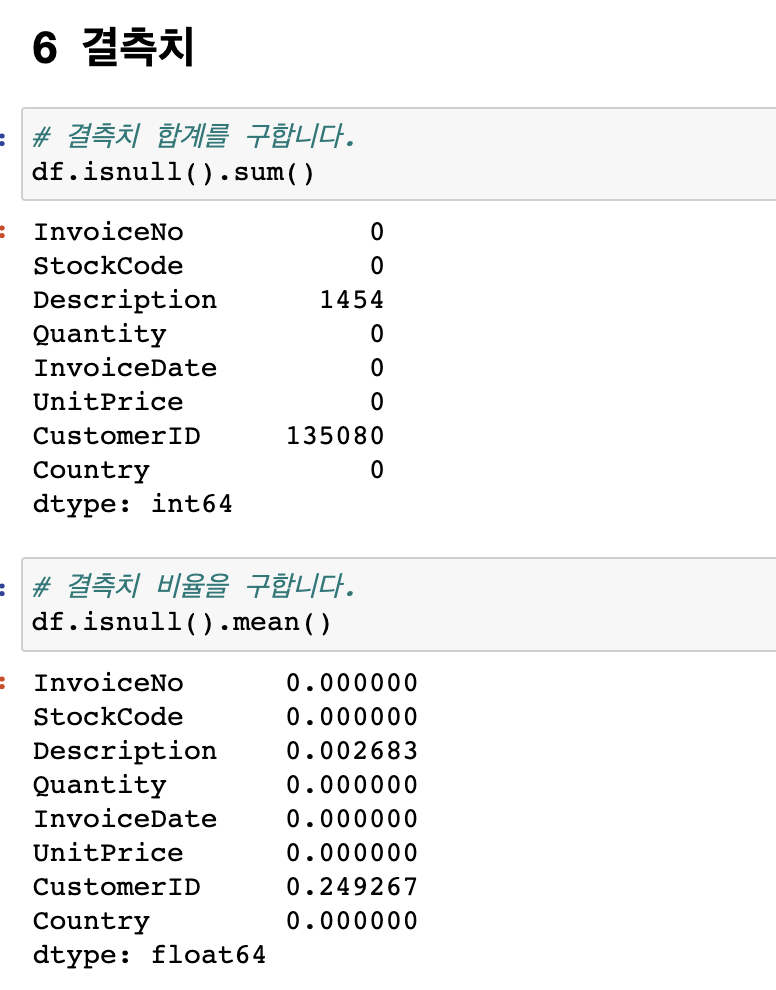
✅Customer ID 의 결측치 =>
CustomerID 0.249267 의 결측치는 무엇을 의미할까요? => 비회원 구매일 가능성 높음
실제 비즈니스이고 회사 업무 일 때는 관련 담당자에게 물어보는 것이 가장 좋음
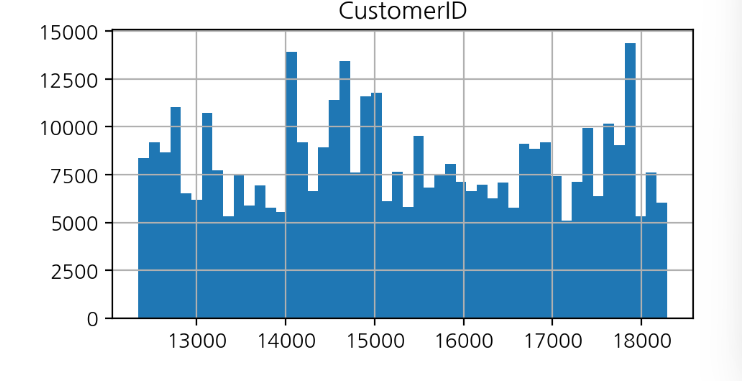
✅세로축(Y축):
히스토그램에서 데이터값이 특정 구간에 속한 빈도수를 나타냅니다.
막대: 각 구간을 나타내는 막대이며, 막대 높이는 해당 구간에 속한 데이터 빈도수
👨💼 JD 직무 기술서
✅ JD를 찾아보면서 데이터 관련 직군에서 필요로 하는 스킬이 무엇인지
✅ 어떤 기술을 준비해야 하는지에 대한 것을 알아보기 위한 목적
✅ 데이터를 통해 어떤 회사에서 어떤 비즈니스를 하고 어떤 직무를 찾고있는지를 알아보기 위한 목적
✅ 다양한 도메인에서 어떻게 데이터가 사용되고 있는지 - 게임, 광고, 제약, 제조, 자동차, 축산, 금융 등
✅ JD를 체계적으로 잘 작성한 회사도 있고 그렇지 못한 회사도 있음
다양한 JD를 보면 그 회사가 나와 맞는 회사인지도 고민해 볼 수 있는 계기가 됩니다.
❓JD를 보다보면 기술 스택에 대한 숙련도
Python ▇▇▇▇▇
Pandas ▇▇▇
Seaborn ▇▇▇▇
참고링크
https://speakerdeck.com/weirdx/99con-junieo-gaebaljayi-iryeogseo-sseugi-idongug
99CON : 주니어 개발자의 이력서 쓰기 - 이동욱
2019년 9월 21일 제3회 구구콘 <이력서> 발표자료입니다.
speakerdeck.com

👨💼 꿀팁 !
✅이력서는 최근순(역순)으로!! & 일관성 있게!
✅파일은 .word나 .hwp보다는 .pdf
✅노션 포트폴리오의 경우 권한 설정 꼭 체크하기
👨💼 Daily Test
정상 동작하지 않는 countplot❓
1) sns.countplot(data=df, x="origin")
2) sns.countplot(data=df, y="origin")
3) sns.countplot(data=df, x="origin", y="mpg")
4) sns.countplot(data=df, x="origin", hue="cylinders")
📌 countplot은 빈도수 세므로 x축 y축 모두 지정하면 X
'Python > ▶ Python & Pandas' 카테고리의 다른 글
| 8주차 WIL (Online_Retail 실습 복습) (0) | 2023.03.02 |
|---|---|
| 6주차 Burger 지수 (0) | 2023.02.09 |
| 6주차 시각화(KOSIS의 산업별 통계) (0) | 2023.02.07 |
| 6주차 Seaborn (0) | 2023.02.06 |
| 5주차 plotly (1) | 2023.02.05 |



