👨💼Key Word
✅ MAU
📝"Monthly Active Users*"의 약자
📝 한 달 동안 특정 앱이나 웹사이트를 사용한 총 사용자 수
💡 만약 어떤 앱이 한 달에 1000명의 MAU를 가지고 있다면, 그 앱은 한 달 동안 1000명의 사용자가 앱을 사용한다는 것을 의미
✅ 요일별 & 월별, 시간대별 구매 빈도수 지표가 중요한 이유 ❓
📝 중요한 segment(세분화)
📝 특정 시간대나 요일
=> 서버 증설 또는 알림 , 프로모션, 광고 등 구매율을 높이기위한 Action Plan 가능
📝 조회수 증가 -> 서비스 개선에 활용
✅ 리텐션
📝 연도, 월, 일, 주별로 구하기도 함
📝 관점에 따라 주기 변경
💡예시
게임을 오픈했는데 1~2달 정도 되었다면 연도, 월별로 구해서 보더라도 큰 의미를 찾기 어려울 것입니다. 그래서 서비스 초기에는 시간대별, 일자별로 보기도 합니다.
서비스를 어느정도 운영하다보면 연도, 월별로 궁금해 지는 시점이 옵니다. 그 때는 연도, 월별로 구해서 보게 됩니다. 위 예시처럼 투자를 위해 리텐션을 만든다면 연도별, 월별로도 만들어 볼 수 있을 것입니다.
💡실습내용
코호트 - 시간, 행동, 규모 단위로 구할 수 있음. 실습은 시간 집단을 기준으로 봅니다. => 리텐션
리텐션 => 월별로 구해서 기존 구매했던 고객이 월별로 얼마나 남아있는지를 구해볼 예정
✅ 코호트 분석 ( Cohort Analysis )
https://datarian.io/blog/cohort-analysis
📝 고객 세분화를 '시간의 흐름'을 기준으로 하는 것
📝 사실 넓게 이야기 하는 사람들은 위의 고객 세분화와 코호트 분석을 따로 구분 X
✅ 코호트 인덱스 ( Cohort Index )
📝Cohort Index는 Cohort 분석에서 사용되는 지표 중 하나로, 특정 기간 동안의 고객 활동을 나타내는 비율
📝고객 Cohort 분석에서 2019년 1월에 처음 구매한 고객 그룹에 대한 2월의 Cohort Index는 2월에 구매한 고객 수를 1월에 구매한 고객 수로 나눈 값입니다.
✅ RFM 분석
구매 사용자 분류에 효과적인 RFM 분석 기법과
RFM을 이용한 사용자 분류(segmentation)에 관한 좋은 참고자료
https://datarian.io/blog/what-is-rfm
https://ko.wikipedia.org/wiki/RFM
고객가치 평가의 척도(RFM의 모든 것)
http://www.itdaily.kr/news/articleView.html?idxno=8371
✅ 이상치의 기준 ❓
Chat GPT
📝히스토그램을 이용한 방법
데이터의 분포를 히스토그램으로 시각화한 후, 그래프에서 벗어난 값들을 이상치로 판단합니다.
일반적으로 이상치를 판단하기 위해 범위를 지정해야 하는데, 3시그마 이상의 값을 이상치로 판단하기도 합니다.
📝상자 그림(box plot)을 이용한 방법
데이터의 분포를 상자 그림으로 시각화한 후, 그래프에서 벗어난 값들을 이상치로 판단합니다.
일반적으로 이상치를 판단하기 위해 IQR(Interquartile range)과 박스 크기의 비율 등의 값을 기준으로 판단합니다.
📝통계 분석을 이용한 방법
데이터의 분포를 정규분포 등으로 가정하고, 해당 분포에서 벗어난 값들을 이상치로 판단합니다.
평균에서 표준편차의 몇 배 이상 떨어진 값들을 이상치로 판단하기도 합니다.
📝도메인 지식을 이용한 방법
해당 데이터의 도메인에 대한 전문 지식을 이용해 이상치를 판단합니다.
예를 들어, 키가 2m 이상이거나 1m 이하인 데이터는 이상치로 판단할 수 있습니다.
📌이상치 제거의 기준은 데이터와 분석 목적에 따라 다름
적절한 기준 필요
데이터 분석하는 도메인 지식의 전문가와 함께 의논하면 더욱 정확한 결과를 얻을 수 있습니다
✅ 이상치와 오류값의 차이점은 ❓
이상치(outliers)와 오류 데이터(errors)는 모두 데이터셋에서 문제가 있는 데이터를 의미하지만, 그 성격과 원인은 다릅니다.
📝이상치는 데이터의 분포에서 벗어난 극단적인 값을 가진 데이터
📝데이터 분석에서 실제 데이터 분포를 제대로 파악하지 못하게 함.
📝 모델의 성능을 왜곡시키는 요인으로 작용
=> 이상치를 탐지하고 제거하는 것은 데이터 분석에서 중요한 전처리 과정입니다.
📝오류 데이터는 입력 과정에서 발생하는 실수, 노이즈, 손상된 데이터 등으로 인해 발생하는 잘못된 데이터
📝데이터의 수집 과정에서 발생할 수 있으며, 예를 들어 계측 장비의 오작동, 인터넷 연결의 불안정 등이 원인
=>오류 데이터를 제거하는 것도 데이터 전처리의 중요한 과정 중 하나입니다.
✅ cut, qcut
cut() : 히스토그램의 bins 와 같은 역할, 같은 길이로 구간을 나눈다.
=> ex )학교 학점에서 절대평가 . 몇 점 이상이면 A학점
qcut() : 같은 개수로 구간을 나눈다.
=> ex ) 학교 학점에서 상대평가 . 상위 10명 A학점
pandas 에서 cut, qcut 을 통해 연속된 수치 데이터를 나눠서 구간화 할 예정
수치데이터 => 범주형 데이터로 만들 때 사용
고객이 한 쪽에 치우쳐져 있지 않고 고르게 분포되어 고객을 좀 더 다차원적으로 보기 위한 방법을 찾기 위해 이 방법을 사용
✅ assign 기능 사용
여러 변수를 한 번에 할당 가능
(지정할 변수명, 할당할 데이터)
rfm = rfm.assign(R = r_cut,
F = f_cut,
M = m_cut)
1. 회원 vs 비회원 구매 ( loc, isnull(), notnull() )
비회원
✅ 'CustomerID'가 결측치( 비회원 ) 인 값에 대해 'Country' 값 가져와 빈도수 구하기
df.loc[df['CustomerID'].isnull(), 'Country'].value_counts()
# df.loc 조건찾기로
1) CustomerID => Null값
2) 'Country' 국가별 빈도수↕
회원
✅ 'CustomerID'가 결측치아닌 ( 회원 ) 인 값에 대해 'Country' 값 가져와 빈도수 구하기
df.loc[df['CustomerID'].notnull(), 'Country'].value_counts()
# df.loc 조건찾기로
1) CustomerID => Not Null값
2) 'Country' 국가별 빈도수
2. 매출 상위 국가 ( nlargest )
국가별 매출액의 평균과 합계
'TotalPrice'를 통해 매출액 상위 10개
df.groupby(['Country'])['TotalPrice'].agg(['mean', 'sum']).nlargest(10,'sum')
✅nlargest( n, columns , keep )
| n | 출력하고 싶은 행의 개수 |
| columns | 크기의 기준으로 삼을 열(컬럼) |
| keep | 중복이 있을 경우에 어떤 값을 우선순위로 할지 |
keep : {'first', 'last', 'all'}, default 'first'
Where there are duplicate values:
- ``first`` : prioritize the first occurrence(s)
- ``last`` : prioritize the last occurrence(s)
- ``all`` : do not drop any duplicates, even it means
selecting more than `n` items.
priortize : 우선순위를 매기다
occurrence : 발생 (발생하는 것)
값들 중에 중복이 있을 경우에 어떤 값을 우선순위로 할지, 동시에 표시할지 고르는 파라미터
3. 매출 상위 국가 ( .style.format() )
df.groupby(['Country'])['TotalPrice'].agg(['mean', 'sum']).nlargest(10,'sum').style.format("{:,.0f}")✅.style.format(':,.0f')
| , | 천 단위마다 콤마(,) 찍기 |
| .0f | 소수점 아래 0자리만 표시(정수만 표시) |
docs 를 봤는데 파라미터 설명이 굉장히 많고 복잡하니까 style.format(',.nf')
, 와 .nf 형태만 기억하자
4. 매출액 상위 10 국가의 Description 구한 뒤 합치기 ( join, concat, merge )
#1 Join 방법
stock_sale.join(stock_desc)
#2 concat 방법
pd.concat([stock_sale,stock_desc],axis=1)
#3 merge 방법
stock_sale.merge(right=stock_desc, on = 'StockCode')

5. 요일 별 빈도수 시각화( x축에 수치 데이터 표현 => table=True )
dow_count.plot.bar(table=True, rot=0, figsize=(12, 4))
plt.xticks([]);
✅table
plot.bar 형태의 시각화는 정확한 수치를 알 수 없기 때문에 X축 레이블에 수치 표시
5. 요일 별 빈도수 시각화( pointplot(estimator=len) )
# pointplot
plt.figure(figsize=(12, 4))
sns.pointplot(data=df, x="InvoiceHour", y="TotalPrice",
errorbar=None, estimator=len).set_title("시간대별 빈도수")
✅estimator=len
"""
estimator : callable that maps vector -> scalar, optional
Statistical function to estimate within each categorical bin.
"""
6. 시간-요일 별 빈도수( background_gradient( axis ) )
hour_dow.style.background_gradient(cmap='icefire',axis=0)
axis = 0 => 열(Column)을 음영처리

axis = None => 모든 DataFrame에 대하여 음영처리

7. 고객 별 구매 빈도수, 평균금액, 총 구매금액
cust_agg = df_valid.groupby(['CustomerID']).agg({'InvoiceNo': 'count',
'TotalPrice' : ['mean','sum']})
cust_aggDict는 Key값이 있음.
Key값은 중복이 되지 않기 때문에 따로 따로 입력해주어야한다!
(mean따로, sum 따로 입력하게 되면 sum 값 하나만 나오게 됨)
8. 잔존빈도
✅ 해당 월에 처음 온 사람 얼마나 남아있는지
✅ 2010년 12월에 처음 온 사람들이 그 다음 달에는 324명 잔존함!
✅서비스에 따라 로그인한 사용자 수 기준 등 다양한 기준으로 리텐션(잔존율)을 구함

9. 잔존율
✅ 잔존빈도를 비율로 보기

Cohort Index에 대한 개념이 잘 안 잡혀서

정리해보면
✅열 기준
InvoiceDateMin = 2010-12-01일 때
Cohort_Index = 1 => 첫달 가입자니까 당연히 100%
Cohort_Index = 2 => 다음달에는 36% 만 잔존함
Cohort_Index = 3 => 그 다음달은 그중 32% 만 잔존함
.
.
.
✅행 기준
Cohort_Index = 1일때
InvoiceDateMin = 2010-12-01 => 이 달 가입자(100%)
InvoiceDateMin = 2011-11-01 => 이 달 가입자(100%)
InvoiceDateMin = 2011-11-01 => 이 달 가입자(100%)
Cohort_Index = 2일때
InvoiceDateMin = 2010-12-01 => 36% 잔존
InvoiceDateMin = 2011-11-01 => 22% 잔존
InvoiceDateMin = 2011-11-01 => 18% 잔존
📌Cohort_index가 1일 때는 해당 인덱스(InvoiceDateMin)가 가입한 첫 달
Cohort_index가 증가할 수록 그 달에 가입한 가입자 수가 얼마나 잔존하나

📌 sns.pointplot( estimator = len ) ?

▼
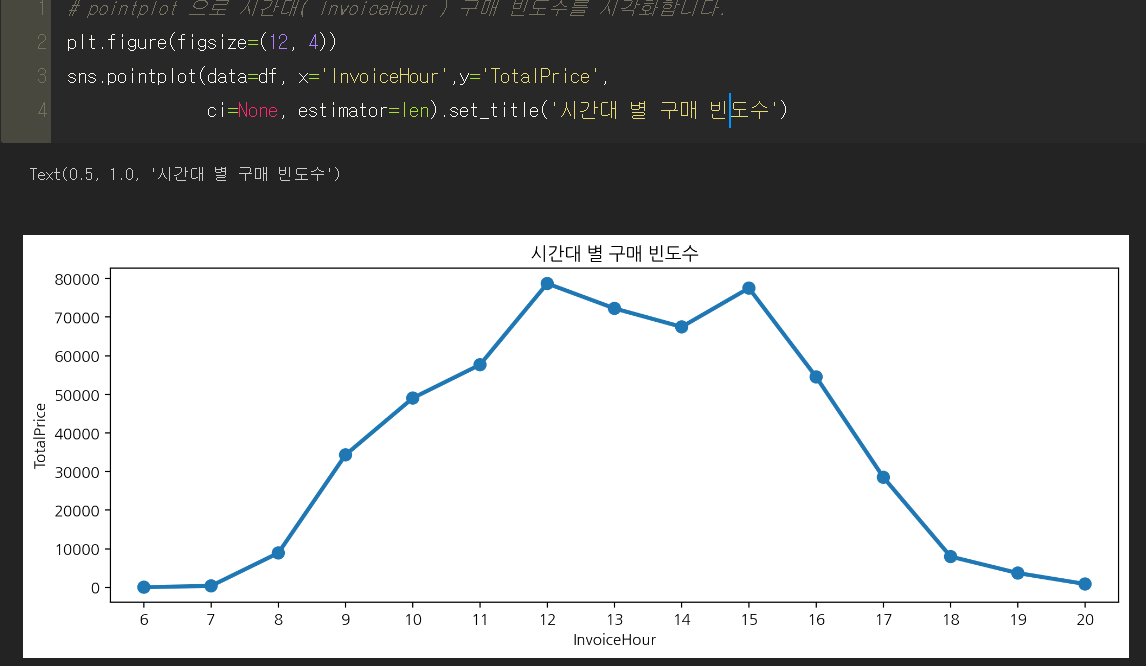
doc랑 구글링이랑 공식document봤는데도 estimator = len이 어떻게 활용되는지 잘 모르겠다...
위에서는 그냥 Total_Price의 값인 것 같은데 아래에서는 어떻게 저런 값이 나오는지 흠
나중에 질문해봐야겠다
▼ estimator = len에 대한 궁금증 해결
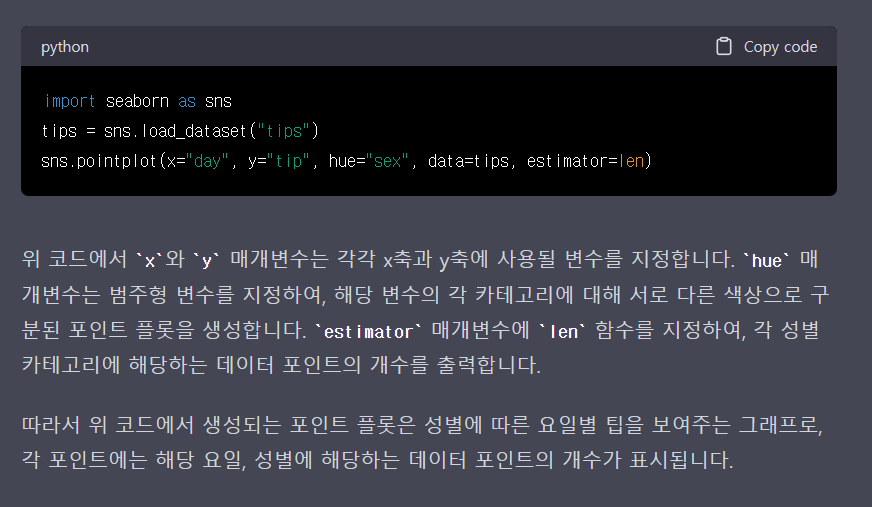
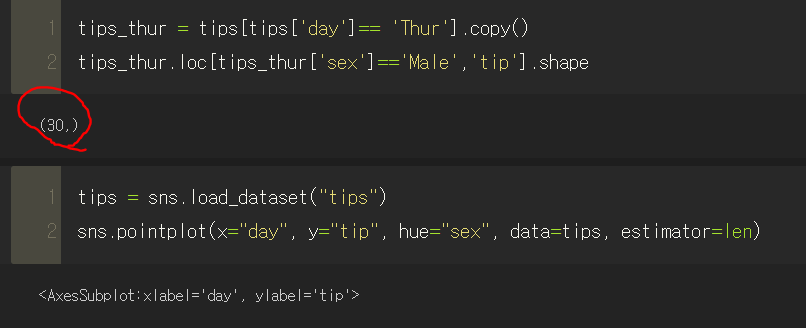
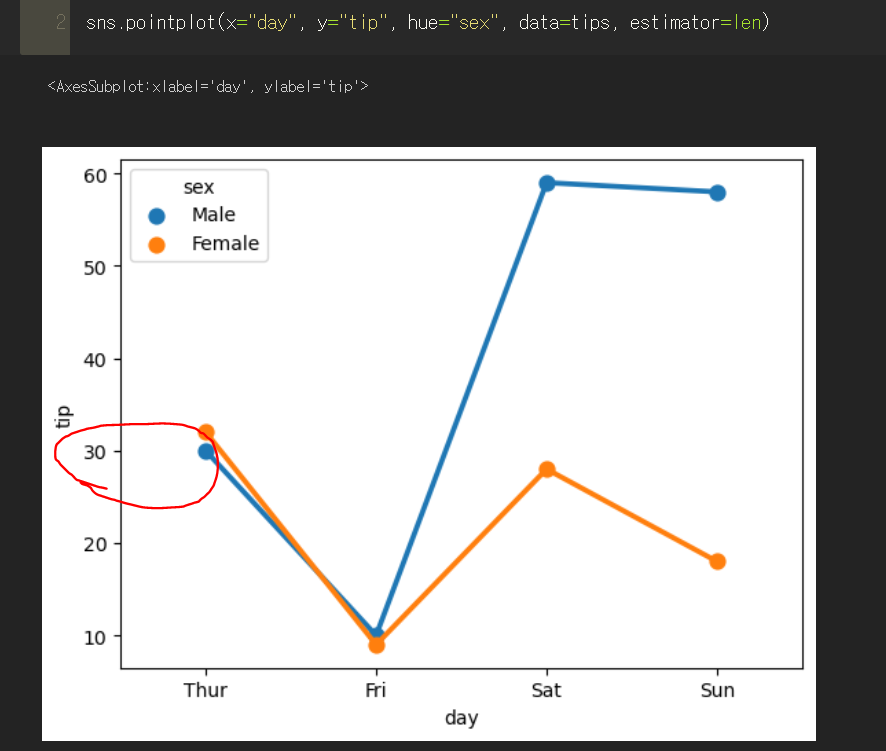
훌륭한 동기분께서 gpt로 예시를 들어주셔서 써먹어볼 겸 나도 gpt에게 한 번 물어보았다.
코드를 직접 작성해서 전처리를 해보니
'목요일'에 tip을 받은 '남자'의 개수를 세어보니 30이었는데
그래프에서 남자의 포인트 위치가 30이다.
그러니까 estimator = len의 뜻은 목요일에 팁을 받은 모든 남자들의 수
내가했던 질문에 대입해보면 저 포인트가 의미하는 바는 해당 시간대에 판매된(매출이 생성된?) 모든 데이터를 합친 개수이다(TotalPrice랑은 상관 없는 듯합니다..!!)
+ 23/03/06
📌 sns.countplot()
x축을 InvoiceYear나 InvoiceMonth로 설정하면
나머지 Y축은 어떤 걸 카운트 하지 ❓ 데이터프레임에 수치형 변수가 여러개면 ❓

아래와 같은 시각화에서 y축을 별도로 지정하지 않으므로 요일 별 (범주형 변수)에 대해 count하는데
데이터프레임에서 어떻게 원하는 변수에 대해 count 할까...❓
📌 transform('min')
이것도 잘 이해가 안간다..어떻게 변환이 되는지는 알겠는데 그냥 외워야 하나?
'Python > ▶ Python & Pandas' 카테고리의 다른 글
| 8주차 비즈니스 데이터 분석 (0) | 2023.02.28 |
|---|---|
| 6주차 Burger 지수 (0) | 2023.02.09 |
| 6주차 시각화(KOSIS의 산업별 통계) (0) | 2023.02.07 |
| 6주차 Seaborn (0) | 2023.02.06 |
| 5주차 plotly (1) | 2023.02.05 |



